前言
对于我这样普通程序员来说,想获取可观的免费数据,最直接的办法就是爬虫了。正好刚学node.js不久,写一个简单的爬虫练练手。废话不多说,直奔主题。
正文
目标
这次要爬的是煎蛋网,找出妹子图2016年度最受欢迎的(oo数量最多的)十张图片。
用到的模块
SuperAgent – 用此来获得网页信息
cheerio – nodejs版的JQuery
具体流程
编写代码前,先打开Chrome分析一下页面源代码 https://i.jandan.net/ooxx/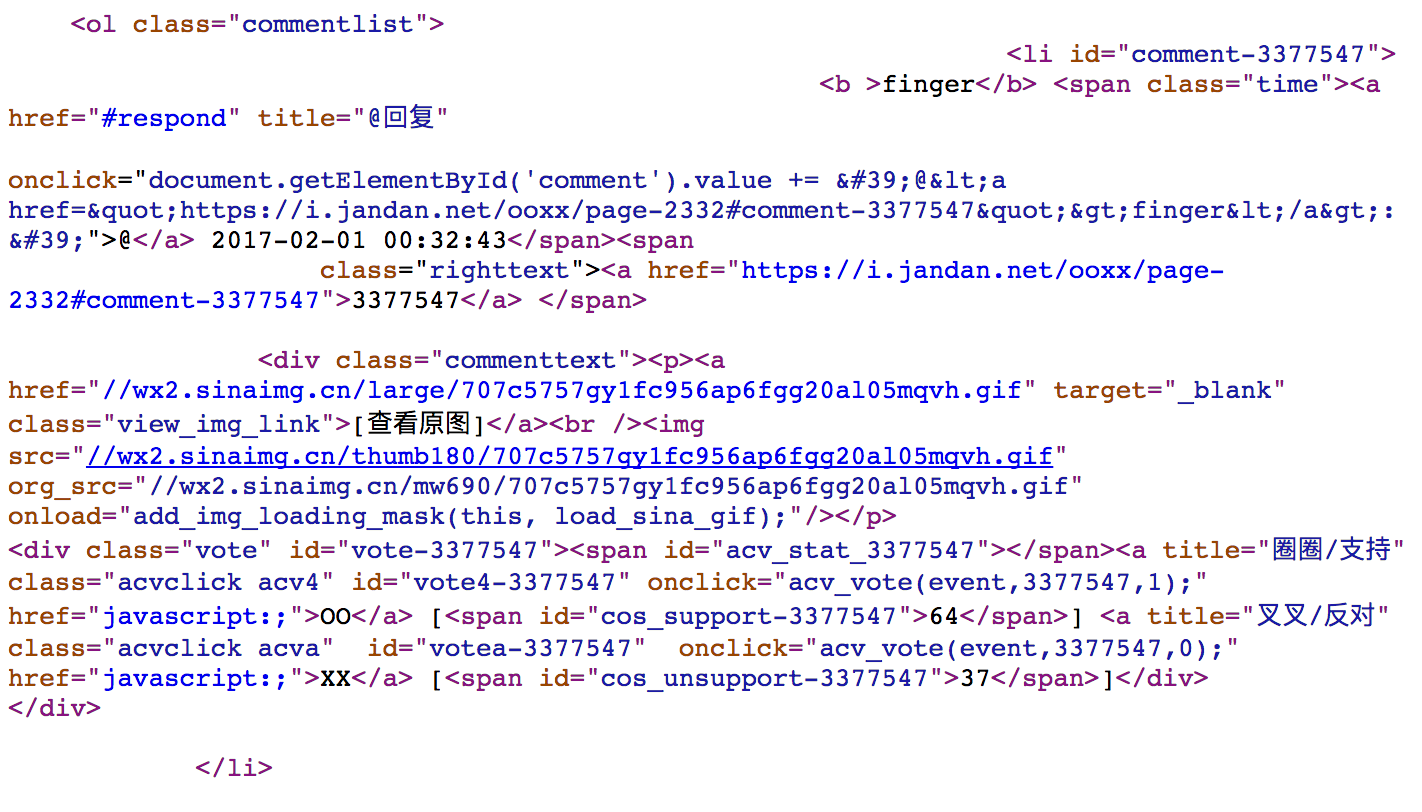
现在开始写我们的程序,创建一个文件夹,进去之后npm init ,填上基本信息之后npm install superagent cheerio --save
新建一个app.js,就可以编写我们的代码逻辑了。
查看全部代码 github
核心代码
|
|
爬到的结果
|
|
说好的福利
前三名

