前言
之前写的爬虫都是直接获取网页内容,解析保存需求数据。然而我后来又遇到一些网页数据使用Ajax获取的,数据不存在于网页的源代码。(高手大神请无视我的见识浅薄) 后来经过学习,终于搞明白这类的网页怎么抓去信息。废话不多说,我们就以马蜂窝为例,做一个简单爬虫。
目标
马蜂窝爬取北京的热门景点。
具体流程
编写代码前,先来到这个网页 http://www.mafengwo.cn/jd/10065/gonglve.html 最下面北京全部景点模块。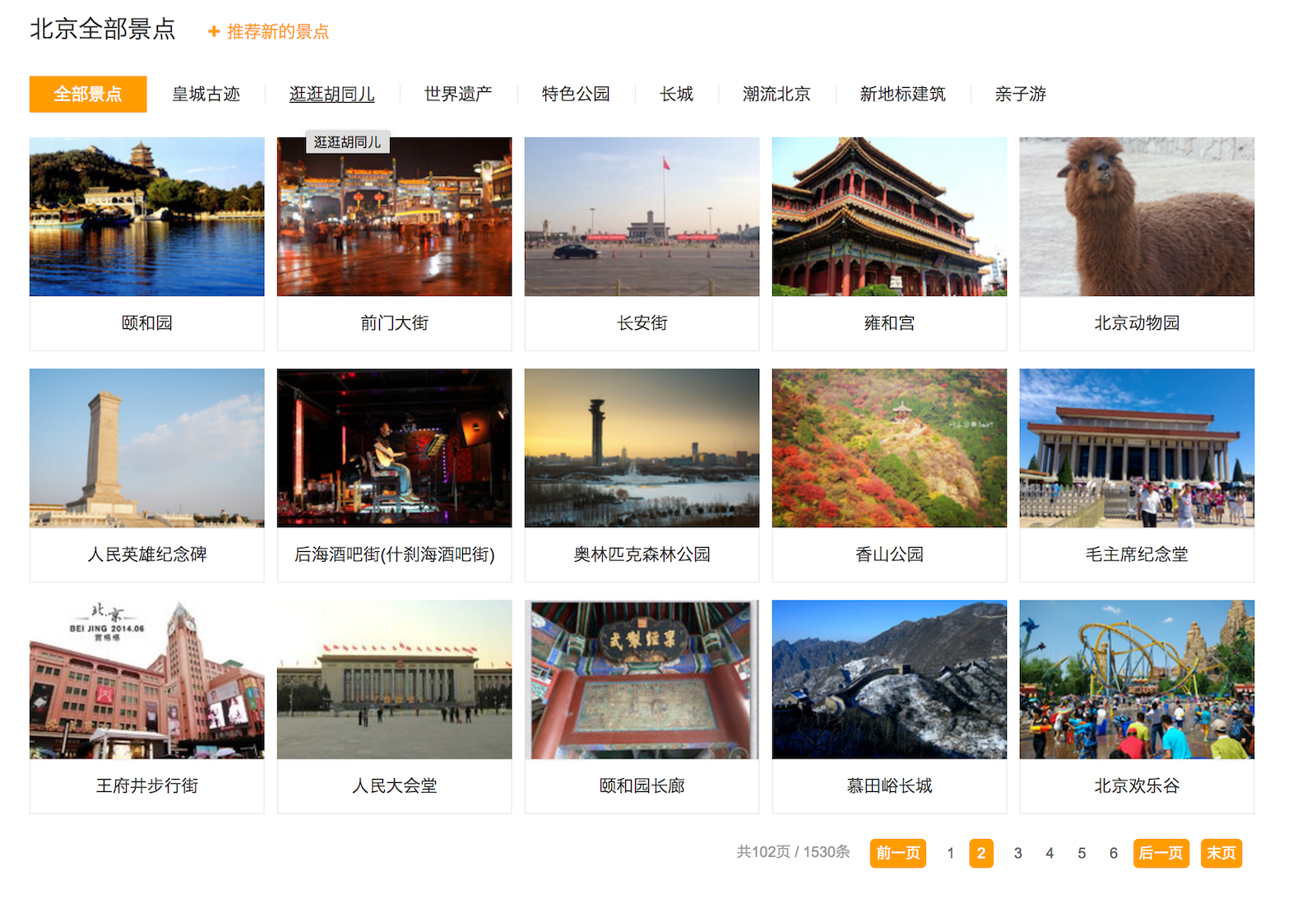
打开chrome inspect under network 是这样的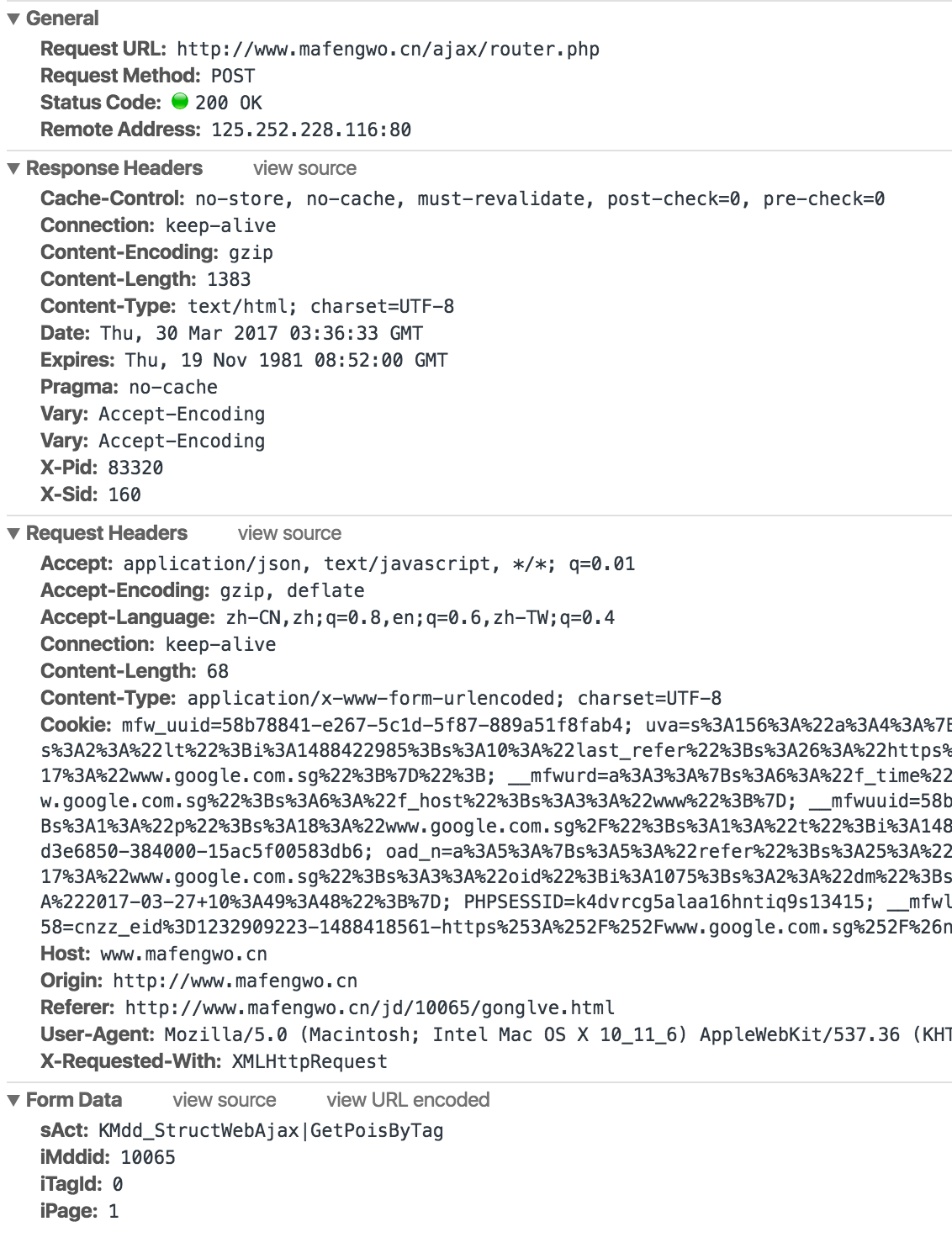
看到这里就可以开始写代码了
核心代码
|
|
这段代码是获取景点列表后,去景点的详细界面获取景点简介。需要注意的是,爬马蜂窝并发的线程不能太多,否则会被封ip,哈哈。
交友
对互联网技术 机器学习 电影 热门游戏 及其它感兴趣的小伙伴可以加我微信好友。大家一起进步,哈哈。